Indoor Challenges
We employ the NYU Depth V2 dataset to define the training data for our RMRC 2013 indoor challenges. The test data consist of newly acquired images, and has been released in October 2013.
Semantic Segmentation
The semantic segmentation training set consists of 1449 RGB-D images from the NYU Depth V2 dataset.

Our evaluation server computes the mean diagonal of the confusion matrix between the predicted pixel labels and the ground truth pixel labels. If a pixel is missing a ground truth label, it is ignored during evaluation. Every object class can be found at least 50 times in the training set. The classes include: alarm clock, backpack, bag, basket, bathtub, bed, bin, blanket, blinds, book, books, bookshelf, bottle, bowl, box, cabinet, candle, candlestick, ceiling, chair, clock, clothes, coffee machine, coffee table, column, computer, container counts, cup, curtain, desk, dishwasher, doll, door, door knob, drawer, dresser, drying rack, electrical outlet, fan, faucet, faucet handle, floor, floor mat, flower, garbage bin, headboard, jar, keyboard, lamp, light, magazine, microwave, mirror, monitor, night stand, ottoman, oven, paper, paper towel, person, picture, pillow, pipe, placemat, plant, plant pot, plate, printer, refridgerator, remote control, sculpture, shelves, shoe, sink, sofa, speaker, stool, stove, stuffed animal, table, telephone, television, tissue box, toilet, towel, toy, tray, vase, wall, wall decoration and window. The training data for the challenge is available here, the test data in here, and the development kit can be obtained here. Note that the segmentation accuracy will be evaluated only inside the mask region (427x561) and not on the full image. The submitted results can either be 480x640 (in which case they will be cropped by our evaluation script) or 427x561.
Depth from RGB
The depth from RGB task consists of 3547 training images taken from the NYU Depth V2 dataset and the Sun3D dataset.

Our evaluation server computes the average relative error per image. A depth pixel's relative error is the difference between the predicted and ground truth absolute depth divided by ground truth depth absolute depth. The average relative depth for an image is simply the average of each pixel's relative depth error over the entire image. Pixels whose depth's are missing are ignored during evaluation. To deal with the inherent ambiguity in the scene scale, we have provided the absolute height of each scene along with the RGB and Depth pairs. The training data for the challenge is available here, and the test set here. The development kit can be obtained here.
3D Detection
The 3D detection task contains 1074 training images taken from the NYU Depth V2 dataset. Each image has been annotated with 3D bounding boxes.
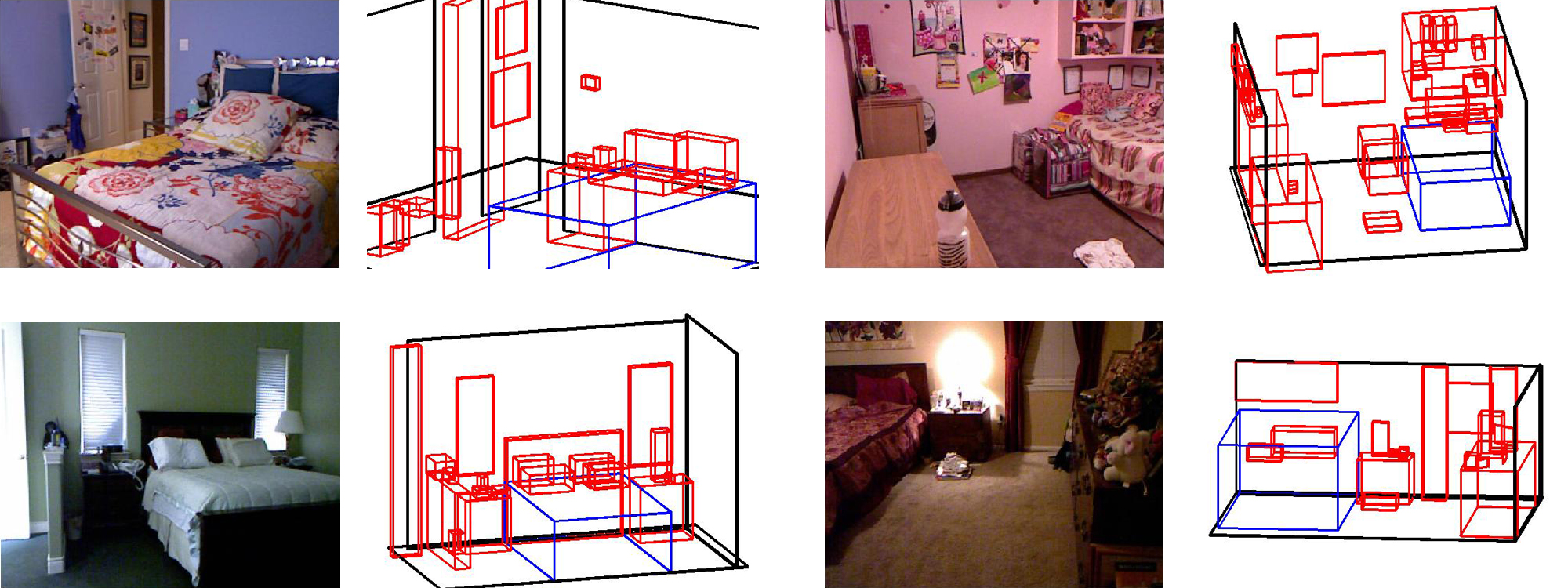
Our evaluation server computes the mean intersection/overlap scores for each of the proposed 3D bounding boxes. All of the bounding boxes are axis aligned in the Z axis (up-down) only. To ensure the Z axis of the labels and predictions are the same, a rotation matrix aligning the 3D scene with the Z axis has been provided. The classes to detect include: bed, table, sofa, chair, television, desk, toilet, monitor, dresser, night stand, pillow, box, door, garbage bin, and bathtub. The training data for the challenge is available here, and the test data here . The development kit can be obtained here.
For any questions, contact nathan (dot) silberman (at) gmail (dot) com

