Projects
Less is More, Faithful Style Transfer without Content Loss - [PDF] // [DEMO]
Nicholas Kolkin, Sylvain Paris, Eli Shechtman, Gregory Shakhnarovich
Abstract: The dominant style transfer framework is based on separately defining ‘style loss’ and ‘content loss’, then finding an image that trades off between minimizing both. The challenge of operating in this regime is that formulations proposed so far for the ‘content loss’ and ‘style loss’ are fundamentally at odds, and generally impossible to simultaneously drive to zero. In this work we show that an explicit content loss is unnecessary. We propose Neural Neighbor Style Transfer (NNST)—a straightforward approach based on nearest-neighbors that achieves higher quality stylization than prior work, without sacrificing content preservation.
Deformable Style Transfer - [PDF]
Sunnie Kim, Nicholas Kolkin, Jason Salavon, Gregory Shakhnarovich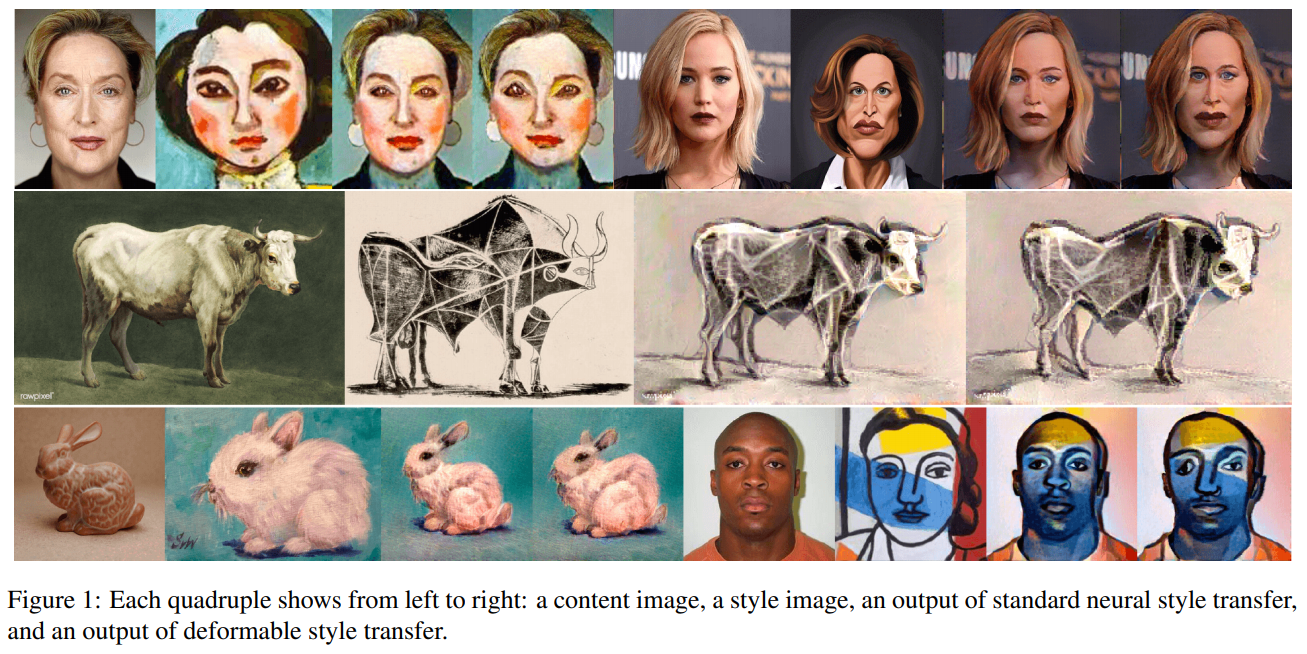
Abstract: Geometry and shape are fundamental aspects of visual style. Existing style transfer methods focus on texture-like components of style, ignoring geometry. We propose an optimization-based approach that integrates texture and geometry style transfer. Our method is the first to allow geometry-aware stylization not restricted to any domain and not requiring training sets of matching style/content pairs. We demonstrate our method on a diverse set of content and style images including portraits, animals, objects, scenes, and paintings.
Style Transfer by Relaxed Optimal Transport and Self-Similarity (CVPR 2019) - [PDF] // [CODE]
Nicholas Kolkin, Jason Salavon, Gregory Shakhnarovich
Abstract: Style transfer algorithms strive to render the content of one image using the style of another. We propose Style Transfer by Relaxed Optimal Transport and Self-Similarity (STROTSS), a new optimization-based style transfer algorithm. We extend our method to allow user-specified point-to-point or region-to-region control over visual similarity between the style image and the output. Such guidance can be used to either achieve a particular visual effect or correct errors made by unconstrained style transfer. In order to quantitatively compare our method to prior work, we conduct a large-scale user study designed to assess the style-content tradeoff across settings in style transfer algorithms. Our results indicate that for any desired level of content preservation, our method provides higher quality stylization than prior work.
DIODE Dataset - [PDF] // [DATA]
Igor Vasiljevic, Nicholas Kolkin, Shanyi Zhang, Ruotian Luo, Haochen Wang, Falcon Z. Dai, Andrea F. Daniele, Mohammadreza Mostajabi, Steven Basart, Matthew R. Walter, Gregory Shakhnarovich
Abstract: We introduce DIODE, a dataset that contains thousands of diverse high resolution color images with accurate, dense, long-range depth measurements. DIODE (Dense Indoor/Outdoor DEpth) is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. This is in contrast to existing datasets that focus on just one domain/scene type and employ different sensors, making generalization across domains difficult.
Training Deep Networks to be Spatially Sensitive (ICCV 2017)- [PDF] // [CODE]
Nicholas Kolkin, Gregory Shakhnarovich, Eli Shechtman
Abstract: In many computer vision tasks, for example saliency prediction or semantic segmentation, the desired output is a foreground map that predicts pixels where some criteria is satisfied. Despite the inherently spatial nature of this task commonly used learning objectives do not incorporate the spatial relationships between misclassified pixels and the underlying ground truth. The Weighted F-measure, a recently proposed evaluation metric, does reweight errors spatially, and has been shown to closely correlate with human evaluation of quality, and stably rank predictions with respect to noisy ground truths (such as a sloppy human annotator might generate). However it suffers from computational complexity which makes it intractable as an optimization objective for gradient descent, which must be evaluated thousands or millions of times while learning a model's parameters. We propose a differentiable and efficient approximation of this metric. By incorporating spatial information into the objective we can use a simpler model than competing methods without sacrificing accuracy, resulting in faster inference speeds and alleviating the need for pre/post-processing. We match (or improve) performance on several tasks compared to prior state of the art by traditional metrics, and in many cases significantly improve performance by the weighted F-measure.