|
Introduction
If low-level vision is about how much information one can independently extract
for each image element,
mid-level
vision is about the interaction between elements or, roughly speaking,
context.
How do we model context? One way is to find a computational/operational
definition for each mid-level visual cue, such as continuity, convexity, or parallelism. An
alternative is to use a generic "context" descriptor, such as
shape context or
geometric blur.
Shapemes
Shapemes, as analogous to phonemes, is the nickname we use for
prototypical local shapes. As we have discovered in our experiments,
such prototypical shapes can capture mid-level cues such as convexity and
parallelism quite nicely, without having any notion of what convexity or
parallelism is. This is a demonstration of the ecological ground of mid-level
vision (Egon Brunswik).
Figure 1 shows an example of the shapemes. We use the geometric blur descriptor
on human-marked boundaries of
a collection of
baseball player photos, align the blurred descriptors according to local
orientation (such that all straight lines are oriented vertically, hence belong
to a single shapeme), and use k-means to cluster them into 64 shapemes.
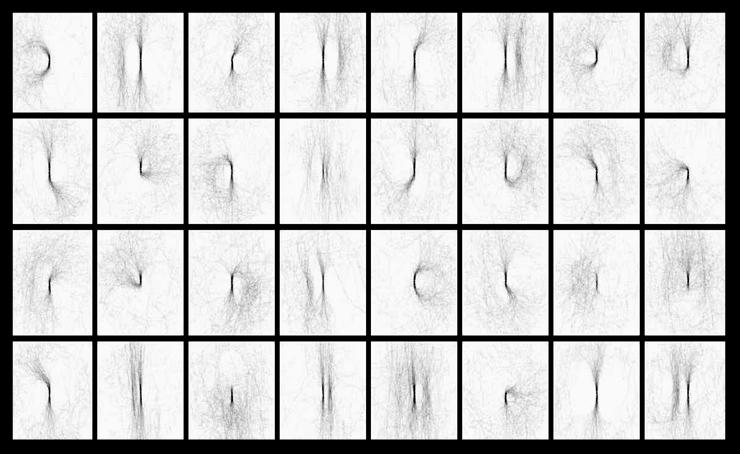
| | Figure 1: an example of shapemes. Shown here is the "average" shape
in each shapeme cluster. Mid-level cues, such as convexity (e.g. row 1, col 1)
or parallelism (e.g. row 1, col 2), can be easily found in this shapeme
representation.
|
|
Shapemes for Figure/Ground Organization
| |

| 
| 
|

| 
| 
| |
Figure 2: some results on shapeme-based figure/ground organization, by
averaging soft shapeme classifier output over human-marked boundaries. Human
subjects provide figure/ground groundtruth labels for images from
the BSDS
dataset. Red indicates a correct classification and blue incorrect.
|
|
|
Shapemes for Boundary Detection

| 
| | Figure 3: precision-recall curves for the baseball player and
the horse datasets. Shapemes, encoding information from a larger context, improves boundary detection. However, they encode information in a generic way, hence less effective comparing to contour continuity cues for the boundary detection problem.
|
|
References
- Figure/Ground Assignment in Natural Images.
[abstract]
Xiaofeng Ren, Charless Fowlkes and Jitendra Malik, in ECCV '06, volume 2, pages 614-627, Graz 2006.
- Familiar Configuration Enables Figure/Ground Assignment in Natural Scenes.
[abstract]
[poster]
[bibtex]
Xiaofeng Ren, Charless Fowlkes and Jitendra Malik, in VSS 05, Sarasota, FL 2005.
- Mid-level Cues Improve Boundary Detection.
[abstract]
[pdf]
[ps]
[bibtex]
Xiaofeng Ren, Charless Fowlkes and Jitendra Malik, Berkeley Technical Report 05-1382, CSD 2005.
|